Anton Biryukov
Scan contact card
A Data Scientist with a passion to make Canadian Energy industry smarter / more efficient leveraging common sense, effective visualization tools and (a bit) of Machine Learning.
Skills
- R
- Python
- Fortran
- git
- linux
- bash
- CSS
- HTML
- Bootstrap
- R-Shiny
- Flask
- Bokeh
- Hugo
- Bokeh
- Altair
- ggplot2
- scikit-learn
- TPOT
- Keras
- mlR
- caret
- selenium
- rvest
- BeautifulSoup
Experience
Data Scientist (full-time)
- Created an in-house automated model training and interpretation library, that boosted the productivity of the data science team
- Lead development of a cloud-hosted application for oil field NPV optimization, interactively demonstrating opportunities in multimillion CAPEX savings
- Mentored junior software developers within the team via providing technical support and helping structure approaches for ongoing ML projects
Graduate Student Intern -> Data Scientist (full-time)
- Developed a multivariate model for an improved wellpad completions design aimed at maximizing value of the land development project
- Worked with a reservoir enginering team on a Bayesian forecasting tool to quantitatively evaluate ultimate recovery and expected cash flow of business development opportunities, with uncertainties
- Prototyped an application predicting geological properties of oil sands reservoirs using DL/ML methods that helped better characterize reservoir quality
- Developed a core image segmentation algorithm using CNNs (YOLO) and computer vision Python libraries (openCV) to distill valuable information from unstructured image data
- Developed user-friendly RShiny applets for data formatting, processing and visualization, contributing to increased efficiency of the workflow
- Integrated and interpreted data from various geophysical and engineering techniques for a better understanding of the wellpad short- and mid-term behavior
Data Scientist (intern), Power Markets
- Worked within quant team to develop algorithms for trading DA-RT spread in CAISO market
- Implemented a method for bidding curve proposal, minimizing the drawdown based on the history of daily price-weather relationship
- Developed a scheduled TransCanada Gas Day summary report scraper to streamline gas traders' model workflow
- Researched free and paid data feeding opportunities to be added into a gas trading strategy
Geophysics Summer Intern
- Streamlined a workflow for a subsurface modelling tool by building upon legacy C++ code, and interfacing it with Python
- Applied the workflow to reveal changes in an oil sands reservoir, aiding in future well drilling strategy
- Quantitatively analyzed the limitations of the approach via sensitivity studies, providing both conservative and optimistic outcomes
Geophysical Data Analyst (contract)
- Developed and implemented new signal processing techniques and configurations resulting in more robust data analysis
- Designed a front-end for a 2D/3D wave propagation solver to streamline seismic data interpretation
- Interfaced and automatized a workflow for an in-depth seismological interpretation, widening the range of services provided by the Company
- Maintained data acquisition and processing systems to ensure timely delivery of data to the client
Portfolio
Working in Oil & Gas / Energy often means the product of your work (code / visualizations / reports) will stay within the walls of the company.
Unfortunately, it’s not in the industry’s habits to open-source valuable contributions, but a trend has recently been set by Equinor to contribute as much as possible to open-source and developer community.
Therefore, here’s a non-exhaustive list of my small and big projects: those shared out with the community or academia as an open source project, or presented at various events, with a schematic of the workflow.
(What celebrity do you sound like?) Diarisation & voice recognition pet project
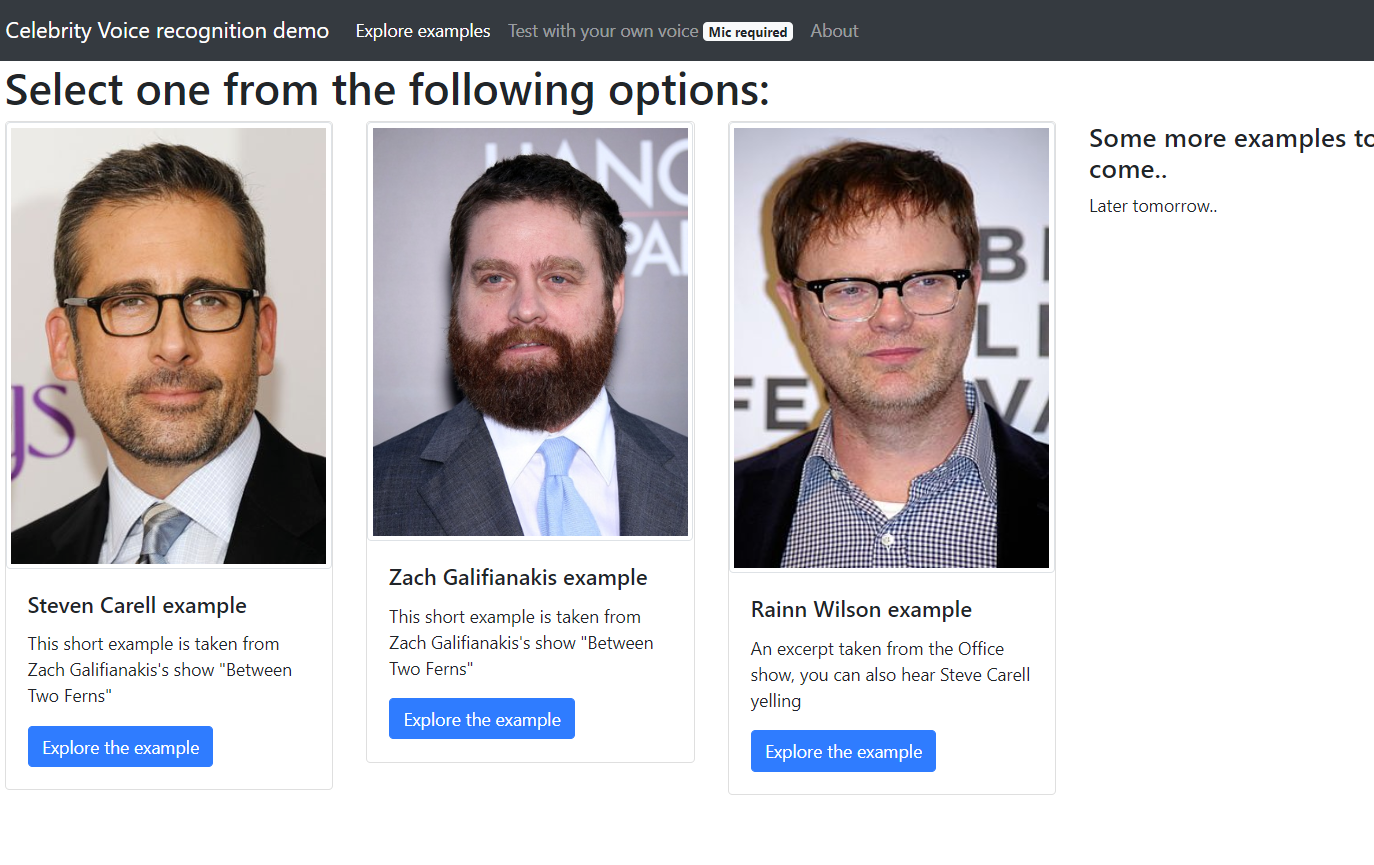
In this work myself and Dan Sola tried to explore the applications in voice diarisation and voice recognition, and what methods are currently popular in solving these problems. As a result, we realized diarisation is still quite vulnerable to noise in the data and often fails to identify the correct number. Therefore, we focused on studying the voice recognition methods, and researched into the work done by VGG group at Oxford. That allowed to turn our little project into a small Flask app that connects to your microphone, records your speech and shows you who you sounded like over time. If there's no immediate access to a microphone, one can explore examples ran on out-of-sample records downloaded from Youtube.
Turn Up the Zinc | Third Place solution
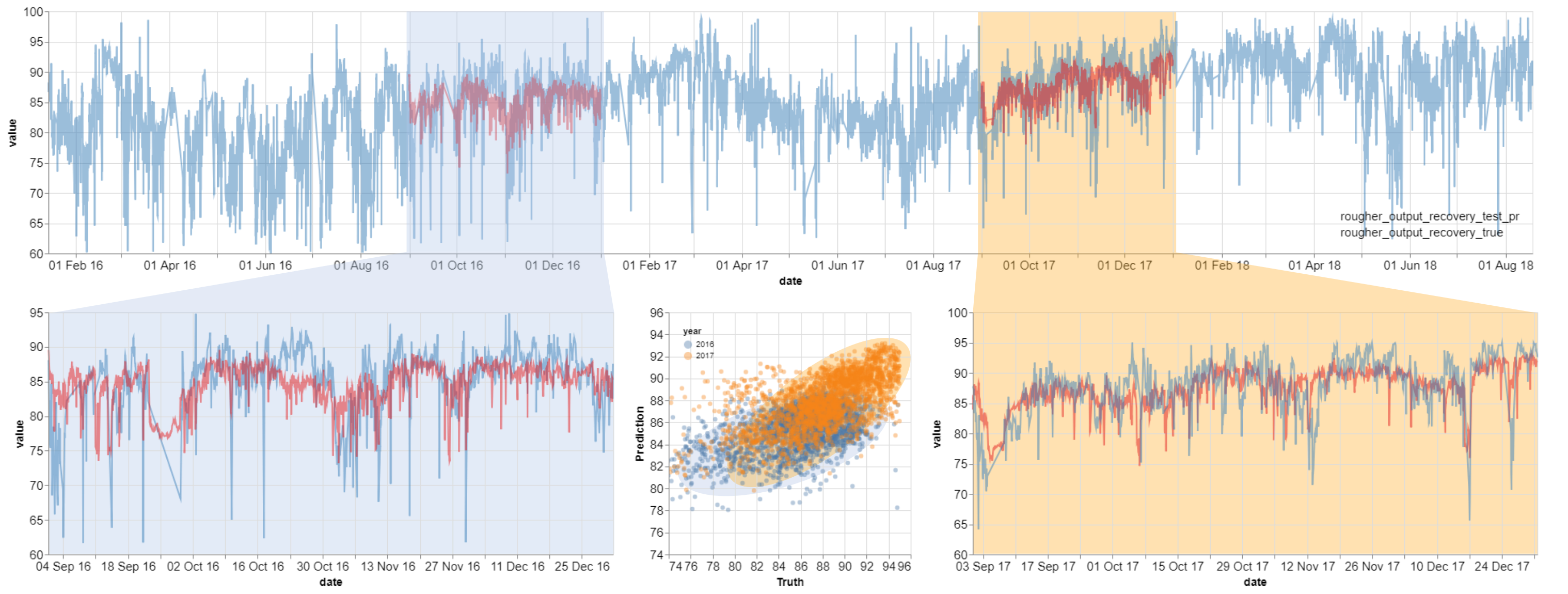
Turn Up The Zinc is a machine learning competition hosted on an Unearthed platform (Kaggle-like with a focus on oil and gas / mining industries). This is a 4-week online competition inviting companies and individuals from around the world to build a prediction model for Glencore's McArthur River zinc-lead mine. Specifically, Glencore wanted a model to accurately predict the rougher zinc recovery and the final zinc recovery for each hourly interval in the provided timeseries data.
Untapped Energy Data Science challenge
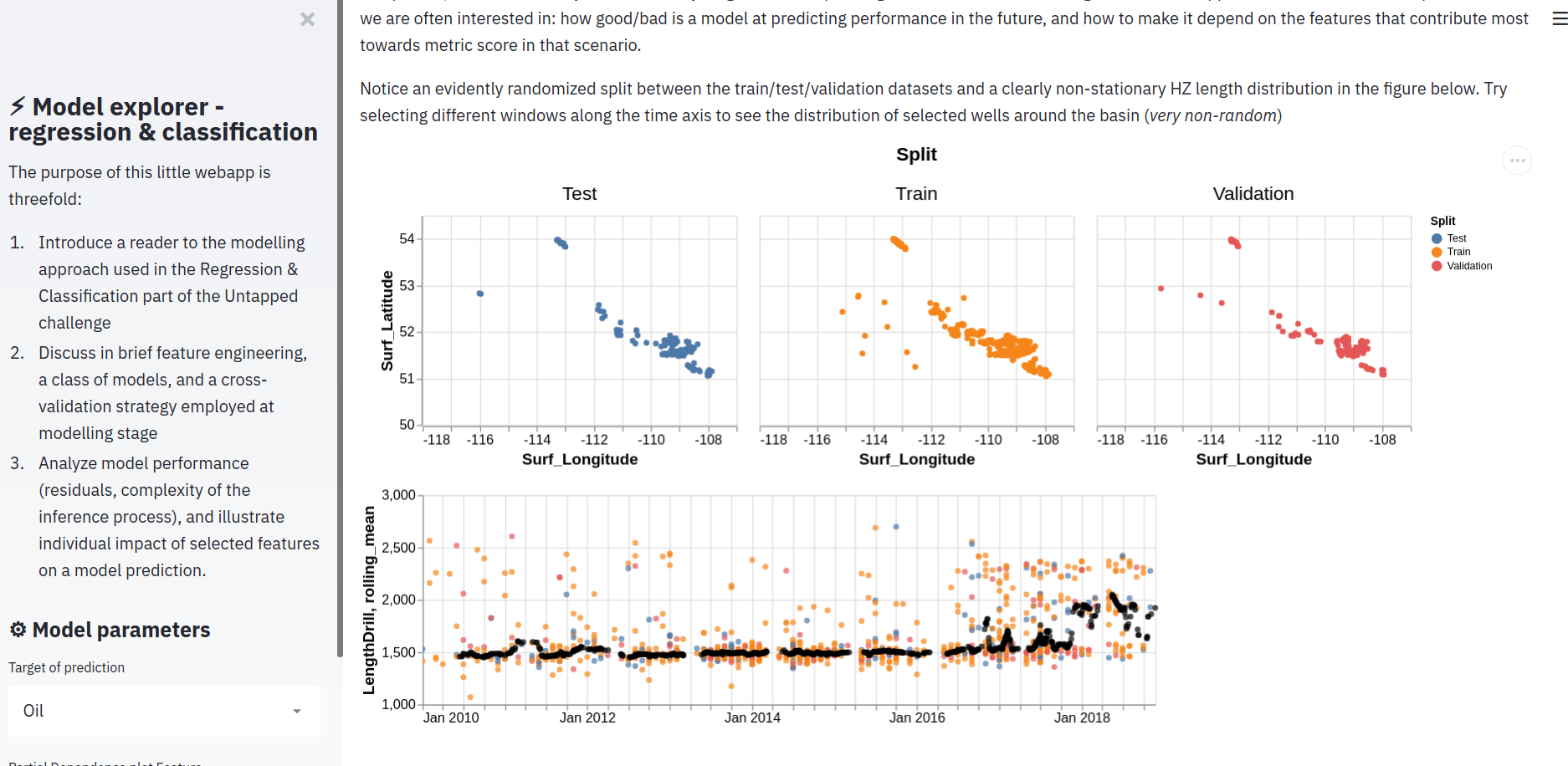
This project was a part of an Untapped Energy Data Science challenge, where participatns were tasked with predicting an IP of an unconventional well in Western Canadian Sedimentary Basin, as well as classify a status of a well (abandoned/active/suspended) using information provided in the data.
Well interaction using pressure timeseries analysis & classification
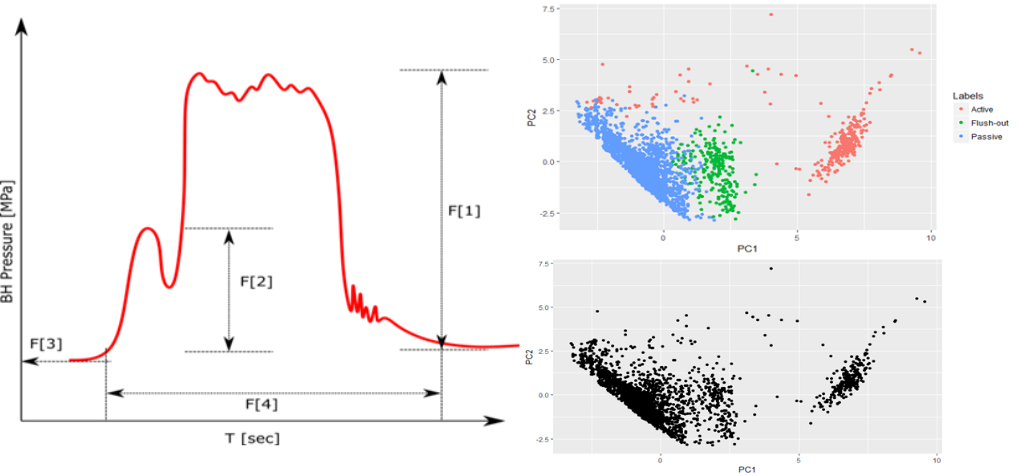
In this work we wanted to quantitatively characterize the interaction between simulatenously completed wells using their pressure timeseries analysis. Our team provided a method for evaluating the degree of fluid connectivity between the wells to assess the extent and complexity of the stimulated network. As a result, one obtains cost efficient, timely means of understanding the stimulated network in order to impact (multi-million $) decisions regarding well spacing, injection rate, perforation design and frac order.
Markov Chain Monte Carlo for well production forecasting
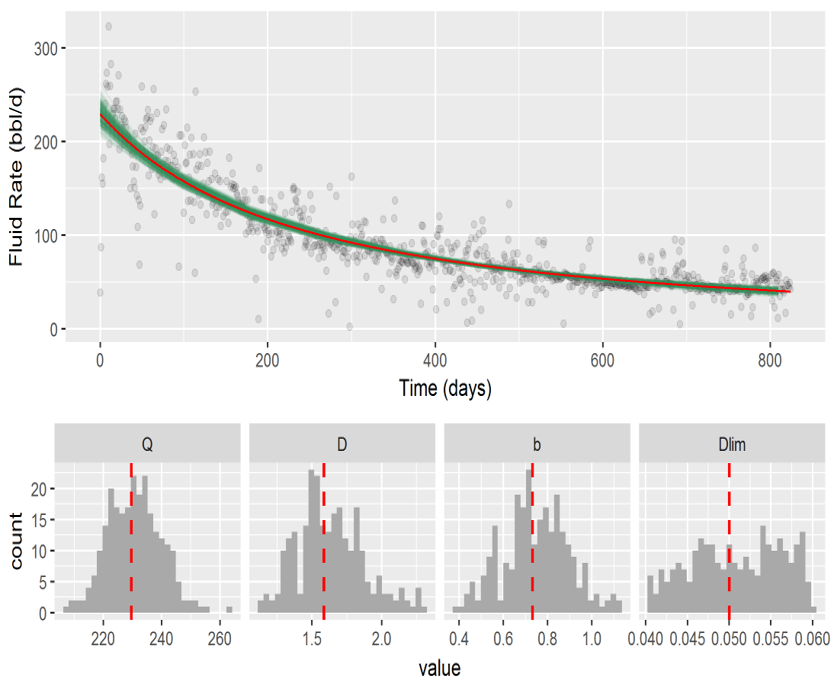
A main goal of this project was to derive a Bayesian (probabilistic) curve fitting methodology, that allowed for quantile regression of a well's production history and then forecasting its performance in the future. The code has been reasonably optimized and parallelized for simultaneous fitting of multiple wells. The applications are geared towards fast evaluation of an asset's future value & cash flow, and its quantiles (i.e. simulate the best, the worst, and the higher likelihood scenario).
Ray Tracing in Fortran with Tomography
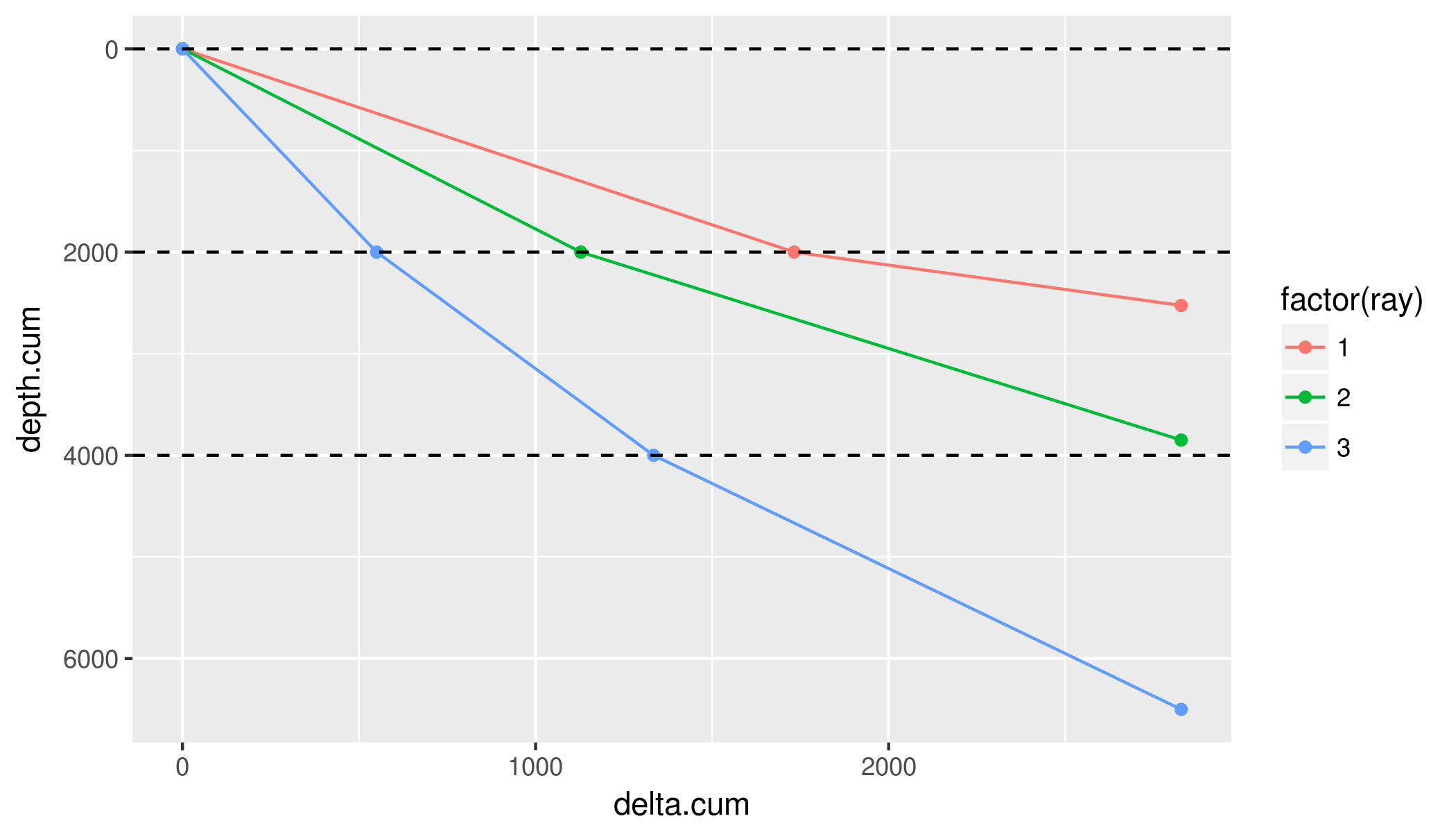
This repository contains the codes for running ray tracing in 1D layered cake model, implemented in Fortran. There are multiple alternatives with better usage / more user-friendly interface to my codes; though they are also "heavier" to leverage MCMC seismic tomography. The main purpose of Ray Tracing here is to be super quick for the particular case of 1D, so I could easily switch different velocity models, and still be able to quickly trace the rays with arrival times.
FMI Inpainting

Here I wanted to have fun with FMI image logs, and see if it is possible to fill those super-annoying gaps that you get in both legacy and new images. Fascinated by Adobe's DeepFill v2 performance on datasets unrelated to Oil and Gas, I wanted to see how it performs in "my domain".
Core Image Localization & Stitching

This project aimed at automating a pretty tedious task of identifying rock quality and lithology from a big dataset of core photographs via application of YOLOv3 for object detection and autoencoder/manifold representation for rock type and quality clustering.
Geologic Facies classification
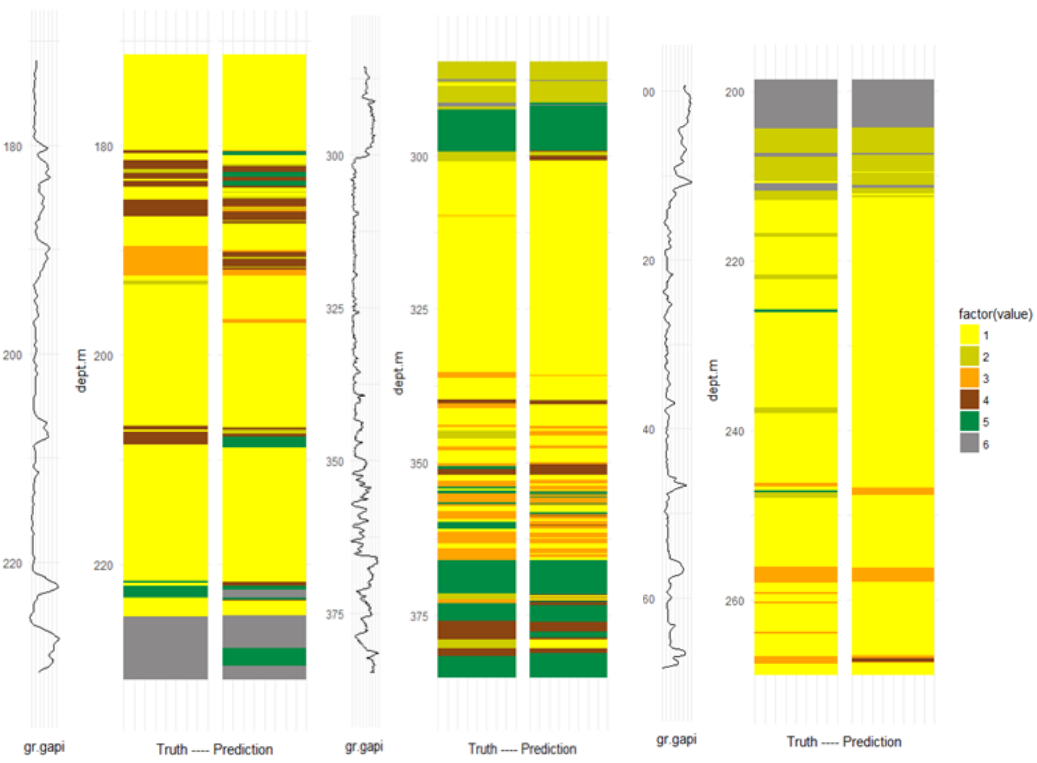
This project aimed at developing a lithology (e.g. rock type) prediction tool, that is robust, scalable, and can be applied / generalized on both public and private datasets.
Publications
A collection of articles, presentations or talks - mainly on Upstream O&G DS/ML or Geoscience topics.
Conference talk - Event Origin Depth Uncertainty—Estimation and Mitigation Using Waveform Similarity
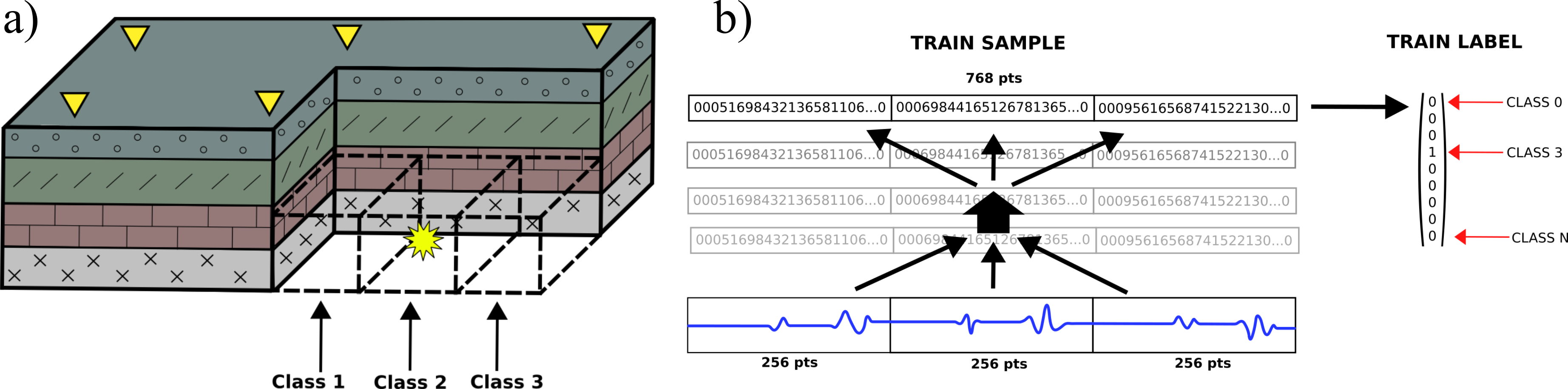
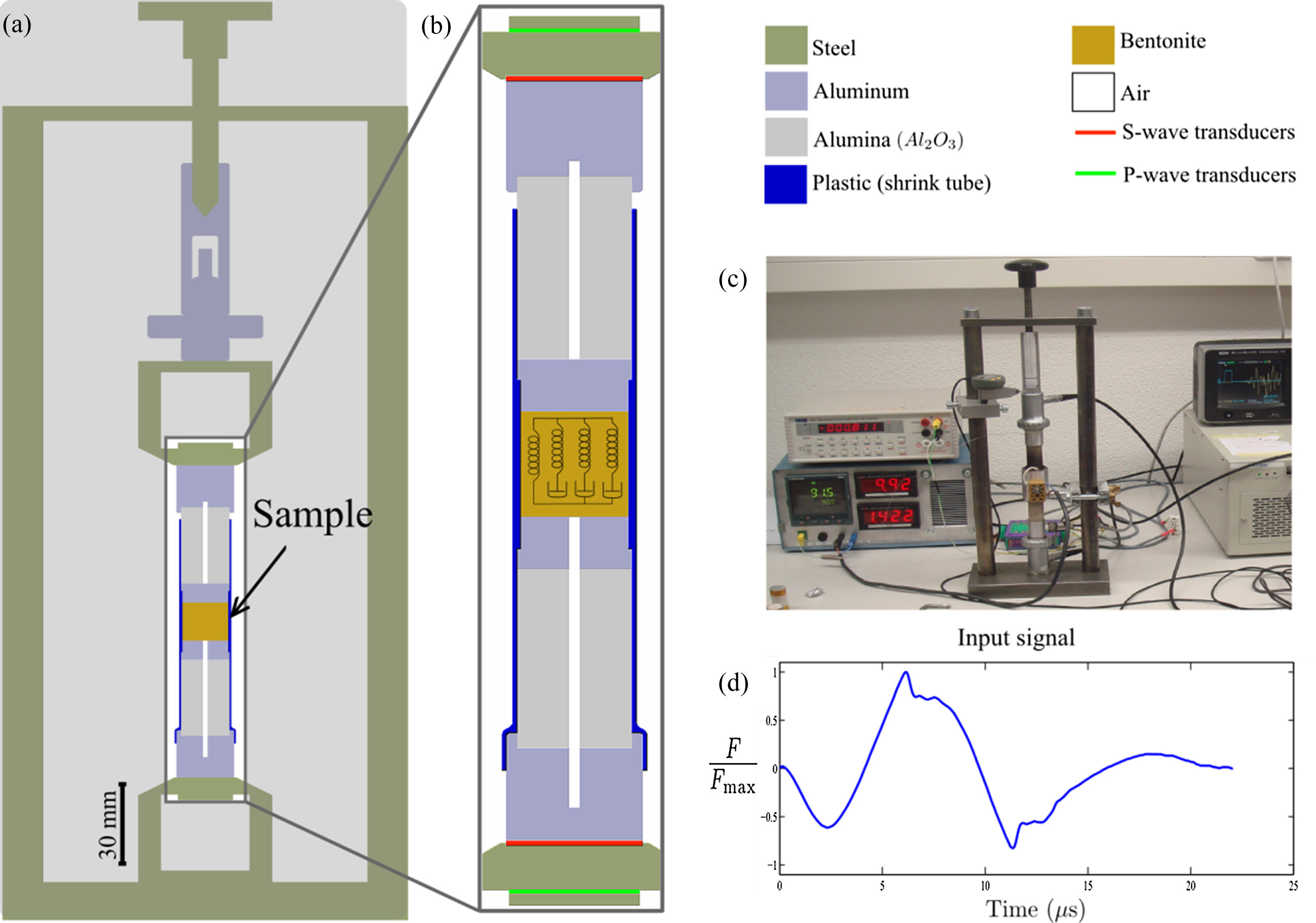
Manuscript - Attenuation of elastic waves in bentonite and monitoring of radioactive waste repositories
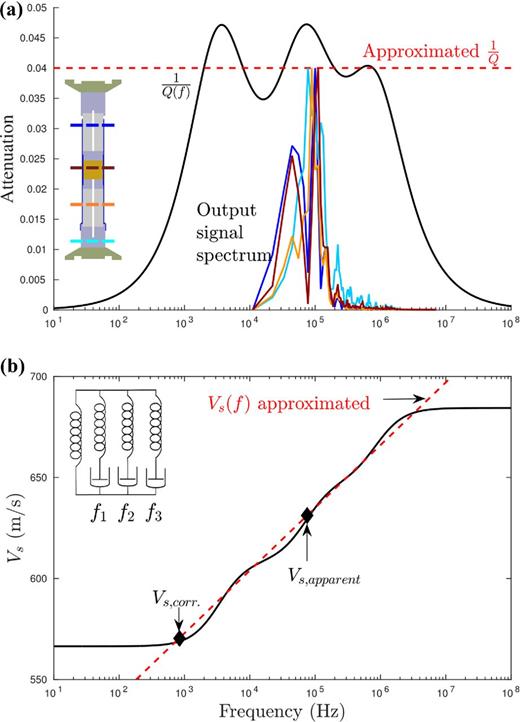
Manuscript - Workflow to numerically reproduce laboratory ultrasonic datasets